コンピュータシステム - 3.コンピュータ構成要素 - 1.プロセッサ - 8.プロセッサの高速化技術
プロセッサが命令を実行するためには、命令解釈・演算・メモリアクセス等を行う必要があり、各々の処理をこなす回路のユニットが存在するが、1つの命令がこれら全てのステップを終えてから次の命令を実行する方式(逐次実行方式)では命令が現在いるステップ以外のユニットは仕事をしない。
これらのユニットを有効利用するために、ユニット間にフリップフロップを挿入して分割し、クロック毎に各ユニットが独立して動作できるようにした上で次々に命令を投入・並列実行する方式をパイプライン処理と言う。これにより各ユニットのハードウェア資源を有効に活用することができ、処理速度が向上する。
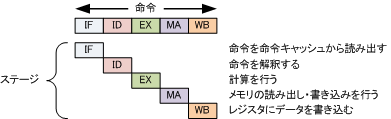
- まずは最初のステージで命令を読み込む(フェッチする)。
- 読み終わる(1クロックが経過している)とステージはその命令を次のステージに移し、次の命令をフェッチする。その間、2番目のステージでは読み込まれた命令のデコードがはじまる。
- それが終わると(さらに1クロックが経過している)すべての命令を次のステージに移す。そして、1番目のステージはさらに次の命令をフェッチし、2番目のステージではデコードを行い、3番目のステージでは最初の命令の演算をおこなう。
- すべての命令を次のステージに移す。3の行程に加えて4番目のステージでメモリアクセスが行われる。
- 同様にして5番目のステージで最初の命令の結果のストアが行われる。
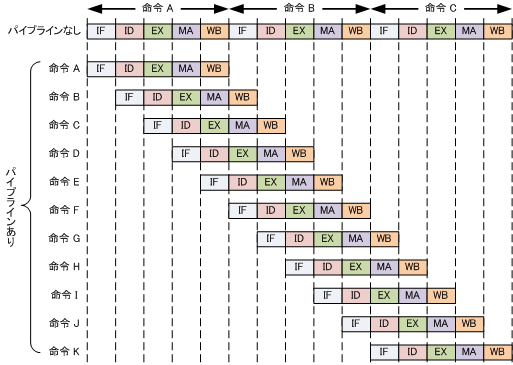
ただし、パイプライン制御は、必ずしも高速化ができるとは限らない。 パイプラインでは、分岐命令の分岐先が決まる前に,予測した分岐先の命令の実行を開始する場合(投機実行)があるため、作成されたプログラムの実行順番どおりに実行されるかどうかは、わからないからです。 たとえば、分岐命令によって、プログラムの実行順番が変わってしまう場合もある。 このように、先読みされた命令を破棄せざるを得ない状態となることを、パイプラインハザードという。 ハザードが発生すると処理速度の低下に繋がる。
パイプラインの方式のステージをさらに細かく分けて並列処理を行う方式。
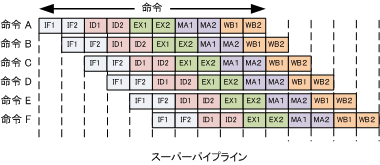
処理装置内部の構成要素を多重化して、複数のパイプラインのステージを用意する方式。
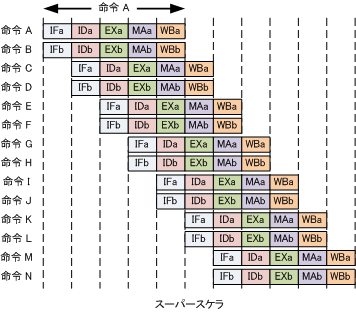
1つの命令に複数の演算操作を指定することで高速化する方式。
プロセッサの高速化技法の一つとして、コンパイルの段階で同時に実行可能な複数の動作をまとめて一つの複合命令とし、CPI (Cycles Per Instruction) 低減を図る方式。
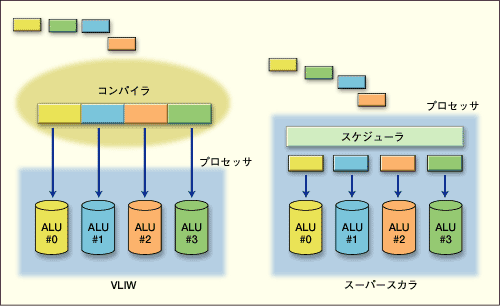
並列に4個の演算器を並べる。それぞれの演算器に対して、たとえば、32ビット幅の命令を供給する。すると、32ビット幅の命令を4個一度に供給するのだから、全体としては128ビット幅の命令長になる。命令長がやけに長いので、「Very Long Instruction Word」の頭文字をとって「VLIW」というわけだ。実に単純明快。そのうえ、一度に1つの命令しか実行できないスカラープロセッサに比べれば、この例の場合であれば、同時に4つの命令を実行できるのだから、性能がよいことも明らかだろう。Crusoe CPU
● VLIWとスーパースカラーの違い
VLIW では、コンパイラによって事前に並列に実行できる処理をまとめ1つの命令としてプロセッサに与える。それに対しスーパースカラーでは、プロセッサ内部のスケジューラがプログラムの並列性を引き出し、同時処理を行う。
マイクロプロセッサ(MPU)の高速化手法の一つ。依存関係にない複数の命令を、プログラム中での出現順序に関係なく次々と実行すること。
プログラムに書かれた順番通りに実行する方式をイン・オーダー実行という。
●イン・オーダー実行プロセッサ
イン・オーダー実行プロセッサでは、通常次のようなステップで命令が実行された。
- 命令フェッチ(命令を読み込む)
- 入力オペランド(計算に必要なデータ)が既に用意されていれば(例えばメモリからレジスタ上に読み込まれて)、命令は適当な実行ユニット(functional unit)に割り当てられ、さもなければオペランドが用意されるまでプロセッサは命令の実行を止めて待つ。
- 命令が適当な実行ユニットで実行される。
- 実行ユニットは実行結果をレジスタファイルに返す。
●アウト・オブ・オーダー実行プロセッサ(OoO)
アウト・オブ・オーダー実行では、命令及び実行結果を一時溜めておく場所を作り、命令の実行を次のように細分化する。
- 命令フェッチ。
- 命令を命令待ち行列または命令バッファ(instruction queue, instruction buffer, reservation stations)に格納する。
- 命令バッファ内の命令は、入力オペランドが得られるまで実行されない。入力オペランドが得られた段階で、バッファ内にそれより古い命令があっても先にバッファから取り除かれ、実行されることになる。
- 命令が適当な実行ユニットに対して発行(issue)され、実行される。
- 実行結果が待ち行列に格納される。
- 古い実行結果が全てレジスタファイルに書き込まれた段階で、上記の実行結果はレジスタファイルに書き込まれる。これを卒業ないしリタイア(graduation, retire)ステージと呼ぶ。
アウト・オブ・オーダー実行の鍵になるコンセプトはある命令の実行に必要なデータが得られない状態でも、プロセッサの動作を止めず他の命令を実行し続けられるようにすることである。インオーダ実行では必要なデータが全部揃わないと(2)の段階で実行が止まってしまう。この点を改善したのがアウト・オブ・オーダー実行である。
アウト・オブ・オーダー実行プロセッサはこの半端な時間(スロット)を他の「準備ができている」命令に当て、後に実行結果の順序を修正することで、順序通り命令を実行したのと同じ結果が得られるようにする。本来のプログラムコードに書かれた命令の順序は「プログラム順」(program order)と呼ばれるが、この種のプロセッサの内部では「データ順」(data order)で扱われる。つまり、データないしオペランドがプロセッサのレジスタに用意される順序である。これら二種類の順序間の変換を行い、同時に出力に論理的な整合性を持たせるためには相当複雑な回路が必要である。プロセッサはまるでランダムな順序で命令を実行するように見える。
命令パイプラインが深くなり、主記憶装置(あるいはキャッシュメモリ)に比べプロセッサが高速になる程アウト・オブ・オーダー実行の威力は増す。例えば、現代のプロセッサはメモリの数倍の速さで動作しており(=メモリを読み書きするのに沢山のサイクル数を必要とする)、バス上にデータが乗るのを待つのは非常にサイクル数を無駄にすることになる(ノイマンズ・ボトルネック参照)。
- シングルコアプロセッサ
シングルコアプロセッサは、プロセッサの基盤の中に命令発行器や演算器などを組み合わせた、ひとつの部品として動作するプロセッサコアが1セット入っている。 シングルコアプロセッサでは、性能向上を図ると、消費電力と発熱量が増大する問題が発生します。一方、マルチコアプロセッサでは、消費電力と発熱量を低く抑えることができます。 - マルチコアプロセッサ
マルチコアプロセッサとは、複数のプロセッサコアを1個のプロセッサの基盤の中に集積したマイクロプロセッサです。2つ以上のプロセッサコアを1個のパッケージに集積したマイクロプロセッサのこと。各プロセッサコアは基本的に独立しているため、それぞれのプロセッサコアは異なる処理を独立して同時に実行できるため、実行効率、速度が上がります。
マルチコアプロセッサはOSからは複数のマイクロプロセッサとして扱われ、動作感もマルチプロセッサ構成とほとんど変わらないため、ユーザやプログラマはマルチコアプロセッサ上での動作を特に意識する必要はない。
デメリットとして、1個のプロセッサパッケージにほぼフルセットのプロセッサコアを複数個詰め込むという性質上、どうしてもプロセッサのサイズは大きくなり、製造コストは高くつく
- 平成28年度春期 問10 パイプライン
- 平成28年度秋期 問10 投機実行
- 平成22年度秋期 問10 パイプライン
- 平成21年度春期 問11 パイプライン
- 平成20年度春期 問17 スーパスカラ
- 平成18年度秋期 問18 パイプライン
- 平成17年度秋期 問17 パイプライン
- 平成15年度春期 問17 パイプライン
- 平成15年度秋期 問18 パイプライン
- 平成13年度秋期 問17 パイプライン
www.it-shikaku.jp