コンピュータシステム - 5.ソフトウェア - 3.ファイルシステム - 3.ファイル編成とアクセス手法
【 順次アクセス 】
シーケンシャルアクセスとも言う。
ファイルの先頭から順番にアクセスする。
レコードを物理的に記録されている順番にアクセスする。
磁気テープ
【 直接(ランダム)アクセス 】
目的のレコードに直接アクセスする。
レコードのアドレスを直接指定してアクセスする。ランダムにアクセスが可能。ハードディスク
【 動的アクセス 】
レコードの位置づけは「直接アクセス」で行い、以降は「順次アクセス」で処理する。
【 順編成 】
ファイル内のレコードを一定の順序で連続した位置に記録する編成である。順次アクセスしか出来ない。
シーケンシャルファイル(Sequential file)とも言う。
データ項目の値や発生順序等に従い、データが順次読み書きされるファイル。
データの更新・追加・削除をする場合は、ファイル全体の読み書きが必要。(ファイルの再作成)
一部レコードのみの更新はできない、レコード末尾への追加のみ可能

レコードを一次元的に配置する方式
ファイル内に格納するレコードは固定長/可変長が選択できる。固定長レコードの場合は改行コードは存在しない。非定型はバイナリーなどに使用する。
【 区分編成 】
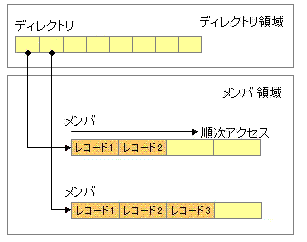
順編成ファイルが複数個集まったもので、順編成ファイルを「メンバ」という単位で名称をつけて名前と先頭アドレスを登録簿(ディレクトリ)に登録する。メンバの先頭へは直接アクセス、メンバ内では順次アクセスとなる。通常は、データファイルとしては使用せず、プログラムファイルやライブラリーとして利用されている。
複数のデータの集合であるメンバに分け、メンバ単位で記録するファイル。 メンバ内の各データは順編成ファイルとなり、メンバ名による索引領域を作ってメンバを管理する。
メンバの内部は、順編成で構成されているので、格納効率がよいという長所がある。
また、レコードを更新する場合でもメンバ単位で再作成すればよいので、順編成よりは処理効率がよい。
【 索引順編成 】
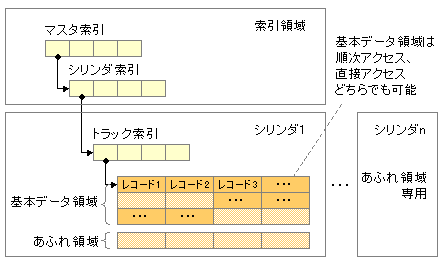
インデックスと言う「索引」がついたファイルでレコードアドレスを検索する際に索引で指定してアクセスする編成法である。アクセス方法は3種類全部が可能である。構成としては以下の通りである。
・基本データ域(プライム領域) データを格納する
・索引域(インデックス領域) 索引を格納する。「マスタ索引」→「シリンダ索引」→「トラック索引」の順に索引される。
・あふれ域(オーバフロー領域) 基本データ域にデータが格納されなくなった時に使用する。これは2種類ある。
「シリンダあふれ域」 各トラックからあふれたレコードを格納する。
「独立あふれ域」 シリンダあふれ域が一杯になったら使用する。
データ領域と索引領域から構成されるファイル。データ領域には順編成と同じようにデータが記録されている。
索引領域にはキーと記録場所との対応が記録される。
あふれ領域の管理が必要となる。
データの更新・追加・削除をする場合は、該当データのみの処理で可能。
基本的に索引部はB+ツリー構造になっています。
Microsoft AccessのデータベースのMDB形式でも採用されている。
データの実体はランダムファイルだが、このままでは検索が出来ないため、頭からなぞって目的のデータを探さねばならず速度的に問題が出る。
そこで、ランダムファイルのキーを別のシーケンシャルファイルに用意しておいて、検索時はシーケンシャルファイルを元にしたインデックス(索引)を使用し、検索を高速化したものがISAMである。
なお、検索処理は高速だが、単純な連続読み込みと、書きこみ処理そのものはとても遅い。インデックスファイルの更新処理などに時間が掛かるためである。
構造が複雑なため、記録効率はあまりよくない。レコードの追加削除を繰り返すことで、あふれ領域のデータが増大して、記録効率やアクセス時間が悪化した場合は、再編成を行い、ファイル構造を作り直す必要がある。
【 直接編成 】
レコード中のキー値をもとに格納アドレスを算出してその位置にレコードを格納する編成。「アドレス変換(ランダマイズ)」と言ってキー値から格納アドレスを算出する。これにより、別のレコードが同じ格納アドレスとなる場合がある(シノニムと言う)。最初に格納したレコードを「ホームレコード」と言い、格納できなかったレコードを「シノニムレコード」と言う。
アドレス変換には、「除算法」「重ね合わせ法」「基数変換法」がある。
シノニムが発生した場合の対処方法には以下の2種類がある。
「シーケンシャル法」ホームレコードのそばに格納する方法。
「チェーン法」ホームレコードの一部にシノニムレコードのアドレスを記録しておき、そのアドレスを利用してシノニムレコードを検索する方法。
あるデータの値に演算処理を行い、その記録場所を決定し、データが読み書きされるファイル。
データの更新・追加・削除をする場合は、該当データのみの処理で可能。
キー値からアドレスに変換する際、キー値をそのままアドレスに適用する場合や、キー値とアドレスの変換表などを用いる場合は、直接アドレス方式という。
キー値から直接、アドレスを導くので、大量のデータ処理には向いていない。
ハッシュ関数など、何らかの計算をしてアドレス変換を行う方式を、間接アドレス方式という。
ハッシュ関数によりアドレスを分散することができるので、大量のデータ処理に向いていますが、異なるキー値でも同じアドレスを指してしまう場合があるので、別途対策を実装しておくことが必要で、この現象を、シノニムと言う。
シノニムを管理することが必要。

【 VSAM編成 】
仮想記憶上で利用されるもので、上記の順編成、直接編成、索引順編成を仮想化した編成法です。ファイルのことを「データセット」と呼ぶ。
・入力順のデータセットは、「順編成ファイル」( Entry Sequenced Data Set, ESDS )
・キー順データセットは、「索引順編成ファイル」( Key Sequenced Data Set, KSDS )
・相対レコードデータセットは、「相対編成ファイル」( Relative Record Data Set, RRDS )
にそれぞれ対応する。
VSAM のレコードには、固定長も可変長も含むことができる。レコードは、コントロール・インターバル ( CI ) と呼ばれる固定長のブロックに編成され、コントロール・インターバルはコントロール・エリア ( CA ) と呼ぶより大きな区切りに格納される。
「CA」コントロールエリア。論理的な制御域で、いくつかのCIを集めたもの。
「CI」コントロールインターバル。いくつかの論理レコードを集めたもの。
【 相対編成 】
直接編成の特別な編成。キー値が連続した値で、直接キー値を格納アドレスとする。
ファイル編成
| ファイル編成 | アクセス法 | 特徴 |
| 順編成 | ・順次アクセス | ・連続した記録の効率が良い(記録順) ・色んな記録媒体に対応 ・直接アクセスはできない |
| 索引編成 | ・動的アクセス ・順次アクセス(キーの昇順) ・直接アクセス(キー指定) |
・索引域(インデックス域) ・基本データ域(プライム域) ・あふれ域(オーバーフロー域) からなる |
| 直接編成 | ・直接アクセス(格納位置指定) | ・間接アドレス方式では、 計算で格納位置を求める→ ハッシング ・シノニムが発生する |
| 区分編成 | ・直接アクセス(メンバ毎) ・順次アクセス(メンバ内) |
・プログラムライブラリとして使用 |
| 仮想記憶編成 (VSAM) |
・順次アクセス ・直接アクセス ・動的アクセス |
・入力順データセット(ESDS) ・相対レコードセット(RSDS) ・キー順データセット(KSDS) がある |
- 平成16年度秋期 問34 ファイルアクセス
- 平成15年度春期 問35 ファイル編成
- 平成14年度春期 問35 ファイル編成法
- 平成14年度秋期 問34 ファイル編成
- 平成13年度秋期 問34 ファイル編成
- 平成13年度秋期 問35 ファイルアクセス
- 平成12年度秋期 問44 ファイル編成法
- 平成11年度秋期 問46 ファイル編成
- 平成10年度春期 問47 索引編成ファイル
www.it-shikaku.jp