コンピュータシステム - 4.システム構成要素 - 2.システムの評価指標 - 1.システムの性能特性と評価
1 システムの性能指標
システムの性能評価には以下のものがある。
●レスポンスタイム(応答時間)
オンライン処理で、入力装置から入力が完了して出力装置へ出力が開始されるまでの時間。
●スループット(処理能力)
単位時間内に処理できる仕事量。パッチ処理ではジョブ数、オンライン処理ではトランザクション数。
●ターンアラウンドタイム
バッチ処理でジョブを投入してからすべての処理結果を受取るまでの時間。
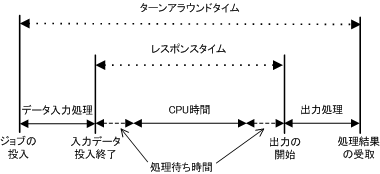
※ 処理待ちの時間とは、ジョブの処理要求が行われてから、システムの資源(CPUや入出力装置)が空くのを待っている時間。
この時間は、処理要求があってから結果の出力が完了するターンアラウンドタイムから、CPUが処理を行っている時間と、入出力装置への入出力時間を引いたもの
処理待ち時間 = ターンアラウンドタイム - CPU 時間 - 入出力時間
●命令ミックス
命令の種類により、必要とするクロック数が異なる場合がある。そのため、処理装置(CPU)の性能を評価するために基準となる命令の平均命令実行時間で表す場合、この基準となる複数の命令を命令ミックスと言う。以下の2種類がある。
- コマーシャルミックス・・・事務処理用の命令ミックス
- ギブソンミックス・・・科学技術計算用の命令ミックス
1秒間に実行できる命令を百万単位(106)で表現したもの。事務処理用の指標。
●FLOPS
1秒間に実行できる浮動小数点数演算の数のこと。科学技術計算用の指標。
【ベンチマークテスト】
標準的なプログラムの実行時間を測定して、ハードウェア、OSを含めた総合的なコンピュータの性能を比較・評価すること。
また、ハードウェアやソフトウェアの単体の性能を評価するためのプログラム。
TPC(Transaction Processing Performance Council)
コンピュータ関連企業などが集まり、トランザクション処理(処理の整合性を保つために1つのまとまりで行う処理)の性能を評価するベンチマーク手法を策定するために設立された非営利団体です。
TPCベンチマークは、CPU性能だけでなく、ハード・ディスク装置、OS、データベース管理システムなどを含めたシステム全体の性能を評価できることが特徴である。
TPCベンチマークの結果は、性能値と価格対性能比で表す。現在、TPC-A、TPC-B、TPC-C、TPC-Dの4種の仕様が定まっている。
- TPC-Aは、銀行の窓口業務をモデルにしたOLTP(オンライン・トランザクション処理)性能を測定するもの。1989年に仕様が定まった
- TPC-Bは、TPC-Aとほぼ同じだがオンライン処理の負荷をテスト内容から除外した。測定結果はtps(トランザクション数/秒)値で表す。端末装置なども含めたシステム全体の価格の公表を義務づけており、異なるベンダーのシステムを価格対性能比で比較できる。1990年に仕様が定まった
- TPC-Cは、TPC-A/Bより複雑な受発注業務をモデルとし、実際の企業内システムに近い。1992年に仕様が定まった。
- TPC-Dは意思決定支援のための複雑なデータベース検索を対象とする。1995年に仕様が定まった。
※「tps」は「Transaction Per Second」の頭文字で、1秒あたりに処理可能なトランザクション数を表す。この数値が大きければそれだけ高い性能が発揮できている。- TPC-Aは、銀行の窓口業務をモデルにしたOLTP(オンライン・トランザクション処理)性能を測定するもの。1989年に仕様が定まった
SPEC(Standard Performance Evaluation Corporation)
コンピュータの実行速度を計測・公表する非営利団体で、ベンチマークプログラムの開発を行っている。特に、プロセサの性能比較としての整数演算の能力を測定するSPECintや浮動小数点演算の能力を測定するSPECfpは、 CPUの能力を計測する手法として広く知られている。Dhrystone
コンピュータの整数演算性能を計測するベンチマーク・テストの一種。実際のプログラムで出現する命令の種類が統計上の割合と位置するように合成したプログラムを動作させる。整数演算や文字列演算向けのベンチマークWhetstone
浮動小数点演算性能を主に計測するベンチマーク。Dhrystonesと同じく、実際のプログラムで出現する命令の種類が統計上の割合と位置するように合成したプログラムを動作させる。
定義した命令群を1秒間で何回実行したかという値「WIPS」によって実行速度を評価する。仮想的なWhetstoneマシンをベンチマークの基準として利用し評価する。Livermore Fortran Kernel
マイクロプロセサの浮動小数点演算の処理性能を測定することによってスーパーコンピュータのベンチマークを構成している。当時、多くのコンピュータで浮動小数点演算のエラーが頻繁に発生していたため、マイクロプロセサの演算性能と、システムの計算精度の両方をテストすることを目的として構築された。Linpack
コンピュータ上で線形代数学の数値演算を行うソフトウェアライブラリに基づいたベンチマークプログラムである。理学・工学で一般的な線型方程式系(大きさは自由)[1]をガウスの消去法で解く速度を測定し、システムの浮動小数点演算性能を評価する。
【 モニタリング 】
プログラムの実行状況や資源の利用状況を測定し、システムの構成や応答性能を改善するためのデータを得ることまたはそのためのツール。
ソフトウェアの性能に関するソフトウェアモニターと、ハードウェアに関するハードウェアモニターなどがある。
コンピュータシステムの性能評価を行う際に、ソフトウェアの性能に関する評価を行うツール。既に運用されているシステムでは、ソフトウェアモニターによる情報や統計データ、課金データなどを収集し、分析することによって、性能上の問題点を把握できる。
コンピュータシステムの性能評価を行う際に、ハードウェアの性能に関する評価を行うツール。
【 目的と概要 】
計画・開発中あるいは稼働中のITシステムに求められるサービス需要/サービスレベルからシステムリソースの処理能力や数量などを見積もり、最適なシステム構成を計画すること。
検討対象となるキャパシティ要件としては、ビジネスレベル(データ処理需要、同時利用ユーザー数など)、サービスレベル(処理トランザクション量、ネットワークトラフィック量など)、リソースレベル(CPU利用率、ディスク利用率、ネットワーク利用率など)がある。
ビジネスレベルのサービス需要がリソースレベルでどのように配分されるかは、システムのアーキテクチャと密接に関係するため、システム増強においては単純なリソースの追加や性能向上だけではなく、システム構成の見直しなども含めた検討を行うことが推奨される。
最適な機種の選定と設備の決定
・ユーザーの要求水準と必要な性能を持つ機種の選定
・使用頻度、使用時間、データ量を考慮したシステムの容量と台数の決定経済性と拡張性への配慮
・将来のデータ増加量を考慮(拡張性)した機能の選択
・資源の共有を考慮し、経済性を考えたシステム構築利用者へのサービスの向上
・ヒューマンインターフェースの検討
・待ち時間を作らないシステム性能の検討
【 キャパシティ・プランニングの手順 】
キャパシティ・プランニングの基本的な作業手順は以下のようになる。
- 構築対象のシステムが実行する処理の種類や量である「ワークロード(負荷)情報」の収集と、それを基にした性能要件の決定(サイジング)
システムにかかる負荷と性能要件を洗い出す。具体的には業務の種類や処理の量、実現すべき処理時間などである。 - 性能要件からリソースのスペックを見積もる「サイジング」
性能を評価する方法
- 静的積算・・・プログラムのDS(プログラム動作時の入出力機械語命令の実行回数)や実I/O回数、要求性能とハードウエアの性能緒元を基に、予測される処理時間を机上で計算する手法。
ターンアラウンドタイム・スループット・CPU使用率などやまた待ち行列理論などを使用して計算する。 - シミュレーション・・・発生する処理の種類と量、評価項目などを定めたモデル・プログラムを作って、コンピュータ上で性能を計算・予測する手法。
- モニタリング・・・実際に稼働している状態でシステムの内部状態をリアルタイムに監視し、性能を観測する。
- ベンチマークテスト・・・目的別にあらかじめ用意した試験プログラムを使い、実システムを試験環境で動作させることにより、性能を予測する。
- 稼働データ分析・・・実際に稼働しているシステムの内部状態情報を時系列にかつ詳細に蓄積しておき、バッチ的に分析し、性能を観測する。
- 経験則・・・過去のシステム構築、運用の経験に基づいて、処理すべきワークロードに必要なリソースや、それによって達成されるであろう性能を予測する。
- 静的積算・・・プログラムのDS(プログラム動作時の入出力機械語命令の実行回数)や実I/O回数、要求性能とハードウエアの性能緒元を基に、予測される処理時間を机上で計算する手法。
- サイジング結果を評価して精度を高めていく「評価・チューニング」
【 スケールアウト 】
スケールアウトは、システムに接続されたサーバーの台数を増やすことで性能を上げる方法です。
水平スケール(水平スケーラビリティ)と呼ばれることもある。
スケールアップより構築コストが安く済む。分散処理を行っているシステムで有効な方法。
個々の処理は比較的単純であるが、多数の処理を同時並行的に行える処理で、データの更新は少なく、読み取りが多くを占める処理に適している。
Webサーバー、サーチエンジン、データ分析処理、VoD(ビデオオンデマンド)、一部の科学技術計算等も、基本的にデータの読み取り処理がほとんどなので、スケールアウトによる処理能力の向上が実現しやすい。
また、スケールアウトは、可用性の増大というメリットも得られる。1台のサーバが障害を起こしても、他のサーバで処理を継続できるシステムが構築できる。
サーバの仮想化機能を使って、ひとつの筐体内で仮想的に複数サーバを構築し、スケールアウトと同等の効果を提供することもできる。このような方式を特にスケールウィズインまたは仮想スケールアウトなどと呼ぶこともある。
【 スケールアップ 】
スケールアップは、サーバーのCPUやメモリといったハードウエアを高性能なものにして処理性能を上げる方法
垂直スケール(垂直スケーラビリティ)と呼ばれることもある。
スケールアップは、OLTP(オンライントランザクション処理)などを行うデータベースサーバーに適している。
【 プロビジョニング 】
設備やサービスに対して新たな利用申請や需要が発生した場合に、必要となる資源一式の割り当て直すこと
【 シン プロビジョニング 】(Thin Provisioning)
ストレージの容量を必要な分だけサーバーに割り当てる技術です。
シンプロビジョニングでは、サーバーが要求する容量のうち、実際に利用される容量のみを割り当てます。
例えば仮想サーバー用に100GBで作成した仮想ディスクが実際には20GBしか使用していない場合、ストレージ上は20GBしか割り当てませんが、仮想OS上では100GBのディスクとして認識されます。
これにより、サーバーが要求するストレージの容量を満たしつつ、ストレージの利用効率を上昇させることが可能になります。
注意点として、サーバー側で利用するストレージ容量が増加した場合、実際に割り当てている容量もあわせて増やす必要があります。 サーバー側が必要とする容量が増加し、実際に割り当てているストレージ容量を超えてしまった場合、ストレージへの書き込みができず、サーバーやアプリケーション側でエラーが発生することがあります。最悪の場合、アプリケーションやプログラムが破損してしまう可能性があります。
サーバー管理者は、サーバーが必要とするストレージを常に把握し、サーバー上で稼働するアプリケーションが正常に動作できるようにする必要があります。
- 平成29年度春期 問13 ベンチマークテスト
- 平成28年度春期 問13 スループット
- 平成27年度春期 問21 出力待ち
- 平成26年度春期 問14 スループット
- 平成24年度春期 問18 ベンチマークテスト
- 平成24年度春期 問19 トランザクション
- 平成22年度春期 問15 ターンアラウンドタイム
- 平成22年度秋期 問18 スループット
- 平成21年度春期 問18 ターンアラウンドタイム
- 平成20年度秋期 問33 スループット
www.it-shikaku.jp