基礎理論 - 2.アルゴリズムとプログラミング - 2.アルゴリズム - 2.代表的なアルゴリズム
整列とは、データを昇順または降順に並べ替えることをいいます。ソート処理とも言います。
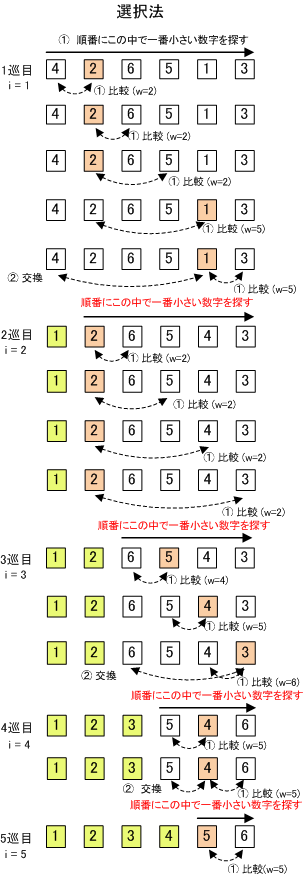
【 選択ソート 】
データの先頭から一番小さい値を探し、見つかれば 1 番目のデータと交換する。次に、2 番目以降のデータ列から一番小さい値を探し、2番目のデータと交換する。これを、データ列の最後まで繰り返す(厳密には、データ列の最後より1つ手前までの繰り返しでよい。一つ前まで交換済みであれば、最後(残り)は必ず最大値になるからである)。
もしデータ数が6個であれば(先頭を1番目とする)、とりあえず、最小のデータ(A[w])を1番目(w=1)とする。1番目(A[w])と2番目(A[2])を比較し、2番目のデータの方が小さければ、2番目のデータを最小値(w=2)とする。次に2番目(A[w])と3番目(A[3])を比較して、3番目のデータの方が小さければ、最小値を入れ換える(w=3)、2番目のデータの方が小さければ最小値はそのまま(w=2)。この最小値(A[w])とデータの比較を最後(6番目)まで行うと、最小のデータ(A[w])が見つかる。そのデータと1番目(A[1])を交換する。
つぎに2番目のデータ(A[2])から始め、最小のデータを2番目のデータとする(w=2)。そして、2番目(A[w])と3番目(A[3])を比較し、最小値を探していきデータの最後まで探したら、2番目のデータと交換する。この最小値を探して交換する処理を最後まで繰り返す。
比較回数・・・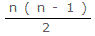 回
回
交換回数・・・各ループで最大1回なので、全体では最大 n-1 回
計算量・・・O(n2)
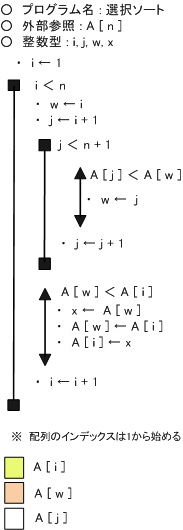
選択ソートのフローチャート(擬似言語)
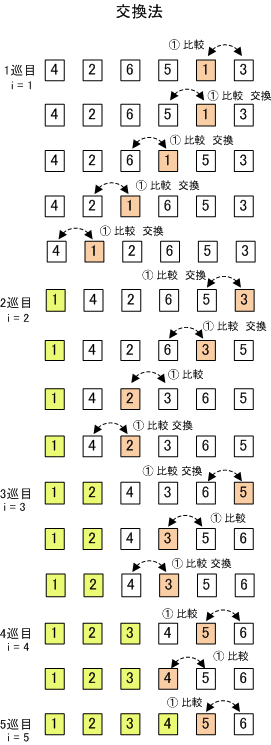
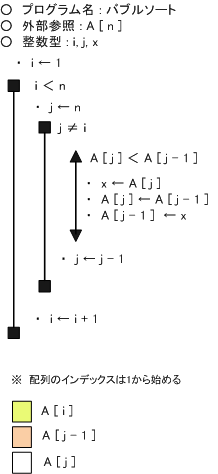
【 バブルソート(交換法) 】
「バブルソート」とは、その名の通り、隣同士のデータを比較・交換しながら、並び替えを行い、最後までその処理を行うとすべてが並び替わっています。
つまり、起点となるデータ(最後のデータ)と隣である要素数-1のデータの比較から開始して、データの大小が逆転していたら、それぞれのデータを交換し、逆転していなければ、1つずらして比較する。徐々に先頭までデータをずらして比較していき、確定する処理を最後まで繰り返します。
もしデータ数が6個であれば(先頭を1番目とする)、6番目(A[6])と5番目(A[6-1]=A[5])を比較し、大小が逆であれば入れ換える。次に5番目(A[5])と4番目(A[5-1]=A[4])を比較して入れ換える。これを最後まで行うと、最後の1番目(A[1])が最小または最大の数として確定する。再度、後ろ(A[6])から比較していき、確定していない部分について比較していき、確定しない最後(2番目まで)(A[2])まで比較していく。これを最後まで繰り返す。
比較回数・・・回
交換回数・・・元のデータ列によって異なるが、一回のスキャンで平均n/2回なので、全体では平均n(n-1)/4回
計算量・・・O(n2)
バブルソートのフローチャート(擬似言語)
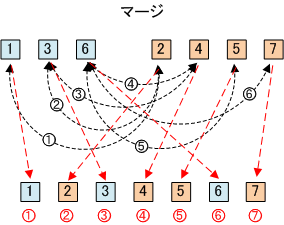
【 マージソート 】
「マージソート」は、既に整列された2個以上の配列を1つの配列に併合する処理を繰り返すことでソートを実現しています。つまり、「分割」して「整列」して「併合」を繰り返します。この方法は、補助記憶装置の大量のデータの並び替えなどに使用される「外部整列法」です。
- データ列を二分割する (通常、二等分する)
- 各々をソートする
- 二つのソートされたデータ列の先頭同士を比較する
- 小さい方(または大きい方)を取り出す
- 3に戻ってこれを繰り返す
- 2番目のステップでは、マージソートを再帰的に適用する。
マージは、データ列の先頭同士を比べ小さい方をデータ列から取り出し、残りのデータ列に対して再帰的に適用する。
比較回数・・・n log2 n 回
計算量・・・最大 O(n log n)
マージソートのフローチャート(擬似言語)
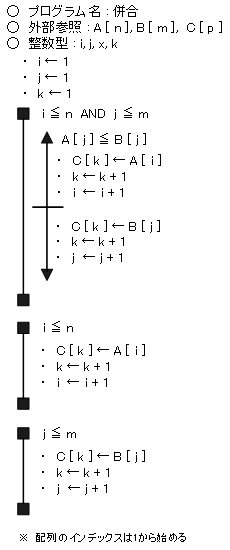
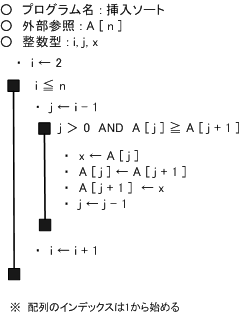
【 挿入ソート 】
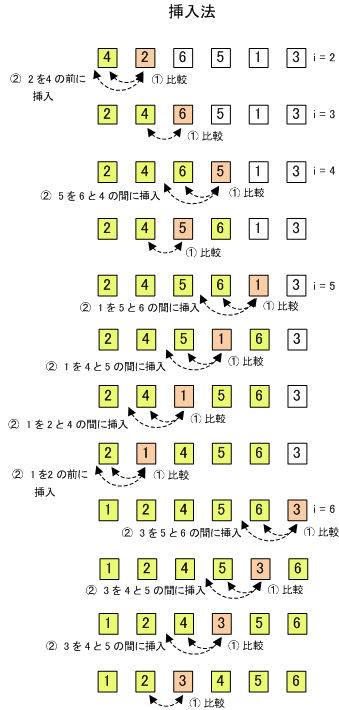
「挿入法」は、データが整列済みと未整列部分から構成されている場合に有効な方法です。整列済みのデータに未整列のデータを挿入していく方法です。
整列済みのデータの一番後ろのデータと次のデータを最初に比較し、大小の順序が正しければ、次のデータの場所は確定し、整列済みとなります。
2番目(A[1+1])と1番目(A[1])を比較し、大小が逆であれば入れ換える。次に、3番目(A[2+1])のデータと2番目(A[2])のデータを比較し、大小が順序通りなら、3番目のデータの比較終了。もし大小が逆であれば、2番目のデータと3番目のデータを入れ替える。入れ替えた2番目のデータ(元々は3番目のデータ)と左側のデータ(1番目のデータ)とを比較し、大小が逆なら入れ替え、正しければそのままにする。これで3番目のデータの位置が決定される。比較するデータを整列済みのデータのグループの中で正しい順に並ぶように「挿入」していく。(挿入する際、左側のデータを後ろに一つずつずらす。)この操作で、3番目までのデータが整列済みとなる(但し、データが挿入される可能性があるので確定ではない)。つぎに4番目以降のデータについて、整列済みデータとの比較と適切な位置への挿入を繰り返す。4番目のデータと左側のデータを比較して、大小が正しければ、その時点で4番目の位置はそのままの位置で順序通りになる。
比較回数・・・最大回
交換回数・・・元のデータ列によって異なるが、一回のスキャンで平均n/2回なので、全体では平均n(n-1)/4回
計算量・・・O(n2)
挿入ソートのフローチャート(擬似言語)
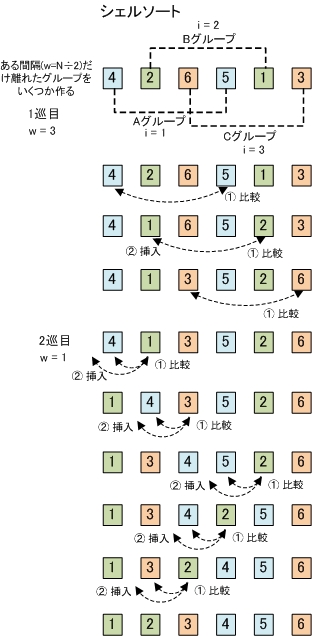
【 シェルソート 】
「シェルソート」は、ある程度整列されたデータに対して有効である。この方法は、「挿入法」を応用して、一定間隔ごとにデータを振り分け、これを挿入法で整列させて、その間隔を順次、狭くしていく方法です。
- 適当な間隔wを決める
スタート時点では、w = データ個数 ÷ 2 とする - 間隔wをあけて取り出したデータ列に挿入ソートを適用する
- 間隔wを狭めて、2.を適用する操作を繰り返す w = w ÷ 2 にする
- w = 1 になったら、最後に挿入ソートを適用して終了
シェルソートのフローチャート(擬似言語)

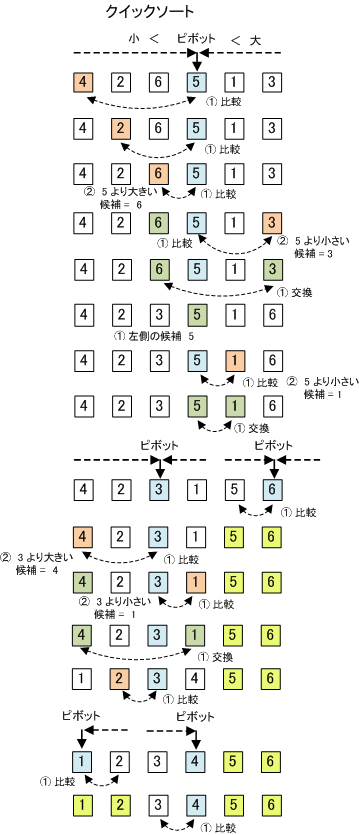
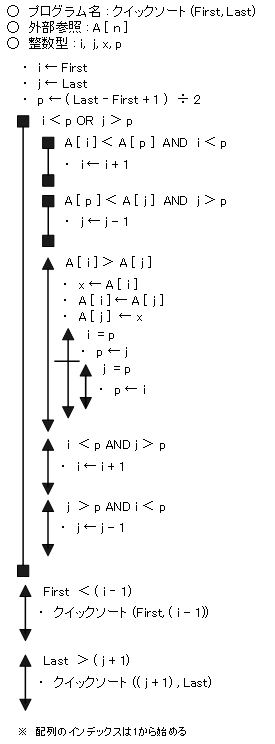
【 クイックソート 】
「クイックソート」は、整列の対象の配列を分割しながら整列を進めます。具体的には、全データから基準値(ピボット)を選び、その値を境にし、より「大きいデータ」と「小さいデータ」のグループになるように振り分けます。この作業を繰り返して行います。また、クイックソートは、「再帰呼出し」と言って、「ある手続きの中から自分自身を呼び出す」方法を用いても実現できます。
- ピボットとして一つ選びそれをP(A[p])とする。
- 左(First)から順に値を調べ、P以上のものを見つけたらその位置をiとする。 (A[i]>A[p])
- 右(Last)から順に値を調べ、P以下のものを見つけたらその位置をjとする。 (A[j]<A[p])
- iがjより左にある(A[i]>A[j])のならばその二つの位置を入れ替え、2に戻る。ただし、次の2での探索はiの一つ右(i+1)、次の3での探索はjの一つ左(j-1)から行う。
- 2に戻らなかった場合(i<j)、iの左側を境界(i-1=Last)にして分割を行って2つの領域に分け、そのそれぞれに対して再帰的に1からの手順を行う。jの右側を境界(j+1=First)にして分割を行って2つの領域に分け、そのそれぞれに対して再帰的に1からの手順を行う。要素数が1以下の領域ができた場合、その領域は確定とする。
注:このアルゴリズムでは、領域の左端の値が領域内で最小かつ同じ値が他の位置に無い場合、ピボットとしてその値を選ぶとループとなってしまう。
比較回数・・・n log2 n 回
計算量 ・・・平均計算量はO(n log n)、最大O(n2)
クィックソートのフローチャート(擬似言語)
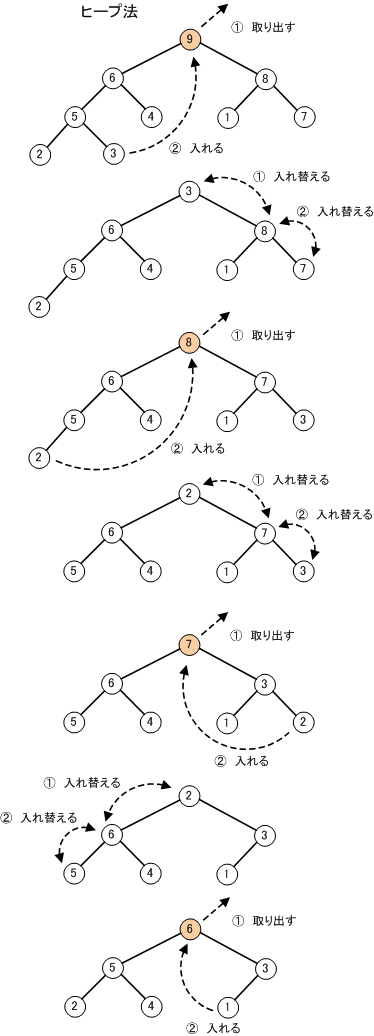
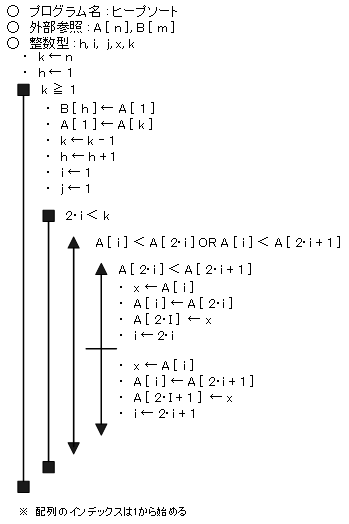
【 ヒープソート 】
「ヒープソート」は、「選択法」を応用した方法で、配列を「ヒープ」に変換します。ヒープとは、ルートに最大値が入る時、親ノード≧子ノード(またはルートに最小値が入る時、親ノード≦子ノード)の条件を満たした完全二分木のことを言います。(昇順の場合は、ルートに最小値が入ります。)
この木をヒープの条件を満たすようにする。すなわち全てのノードの子はその親より小さい値になるようにする。 これは
- ノードが子を持っていないならそのまま。
- ノードが一つしか子を持っていないなら子と自分の値を比べて子の方が大きいなら入れ換える。
- ノードが二つの子を持つ場合
両者の子以下の木構造をヒープ構造に変換する(再帰呼び出しで行う)。 - 自分の値と二つの子の値を比べて、最も大きい値が子の場合入れ換える。
- 入れ換えが起きたなら、入れ換えが起きた方の子以下の木構造をもう一度ヒープ構造に変換する。
という処理を再帰的に行うことでヒープ構造が生成される。
「ヒープ」とは、以下の条件を満たす「2分木」です。
●完全2分木である。
●root要素が最大値(最小値)を持つ
●どの親子関係でも「親>子または、(親<子)」のような一定の大小関係が成立している。
整列の比較回数は(要素数がn個の時)
平均比較回数・・・ n Log2 n 回
計算量・・・O(n log n)
ヒープソートのフローチャート(擬似言語)
降順に並べ替える場合
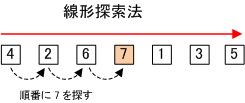
探索(サーチ)とは、大量のデータの中から、目的のデータを見つける手続きのことをいう。
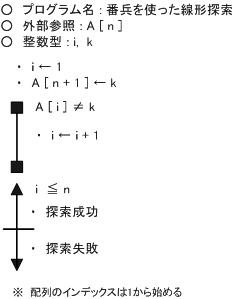
【 線形探索法 】
先頭から順番に1つづつデータを探していく方法。リニアサーチや順次探索法ともいう。
線形探索法では、配列データの最後の次に探すデータと同じデータを入れておくことがある。これを番兵という。
番兵は、探す要素が n 個なら n + 1 個目に番兵を入れる。
番兵を使うことで終了判定が容易になる。
こうすることで、検索している値は必ず見つかる。プログラム的には、検索値が見つかるまでとすることができる。
要素数が n 個の場合、平均探索回数は、( n + 1 ) / 2 回となり、最大探索回数は、n 回となる。
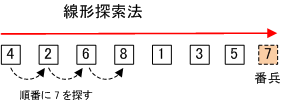
線形探索のフローチャート(擬似言語)
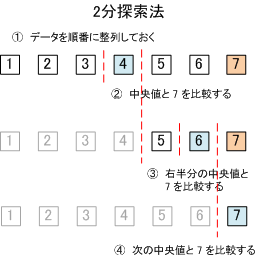
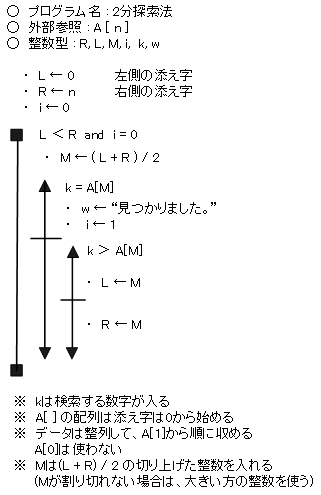
【 2分探索法 】
バイナリサーチとも呼ばれる。
順番に整列されたデータのうち中央の要素のデータと探索データを比較し、中央値でデータを2分し、中央値より大きいか小さいかでその前半分のデータか後半分のデータのどちらかを使うか判定する。これを繰り返していく。
先頭から順番に探していく線形探索法より、高速に探すことができる。要素数が n 個の場合、平均探索回数は、log2n 回となり、最大の探索回数は、log2n + 1 回となる。
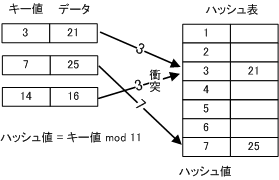
【 ハッシュ表探索法 】
今までのデータ構造は、基本的にデータの先頭から目的のデータを探す順次探索でしたが、目的のデータが最後の方にあった場合は時間がかかります。そこで、データのキー値やデータ値から計算によってデータを格納する場所を決定し、探索時に同じ計算によって格納場所を見つけるハッシュ法があります。これは直接探索法の1つです。
格納場所の計算のための関数をハッシュ関数といい、その結果をハッシュ値(ハッシュキー)という。
ハッシュ値とデータを格納している表をハッシュ表(ハッシュテーブル)という。
具体的な手法ハッシュ関数を示します。
- 自乗・中央法
キー値を自乗し、その中央の数字を使います。1234ならば、1234 × 1234 = 12342 = 1522756より、中央の2275がハッシュ値です。0である桁数が多い場合は不向きです。
- 除算法
キー値に最も近い素数で割った余りをハッシュ値とします。
- 基数変換法
10進数以外で表したキー値の下位の桁を使います。例えば、1234(10)=2578(13)より、578をハッシュ値として使います。
別々のデータからハッシュで得られる値が同じになってしまうことがあります。これを衝突と言い、先に格納されていたデータをホーム、後のデータをシノニムと言います。衝突の対策を次に示します。
- シーケンシャル法
ホームが格納されていた次の場所にシノニムを格納します。その場所も埋まっていた場合、空いている場所が見つかるまで順次探索します。
- チェーン法
シノニムを全く関係ない場所に格納し、その場所のアドレスをポインタでリストにつなぎます。
- オープンアドレス法
シノニムを別のハッシュ関数により再ハッシュします。最初に用意したハッシュ表の大きさを超える量のデータを、格納することはできません
再帰とは、定義や関数の中で自分自身を再度呼び出して利用できる仕組みのことを言う。
再帰を使うと、処理手順が短くなる、プログラムがシンプルになるというメリットがある。
木構造やグラフ理論を使ってデータを探索するための手法。
深さ優先探索、幅優先探索、最短経路探索等がある。
配列に格納されている文字列から特定の文字を探索するアルゴリズムのこと。
文字列から特定の文字列を照合しながら探索するので、文字列照合アルゴリズムとも呼ばれる。
文字列探索には、以下のアルゴリズムがある。
- 順次探索法
配列の先頭と文字列の先頭とを一文字ずつ照合していく方法
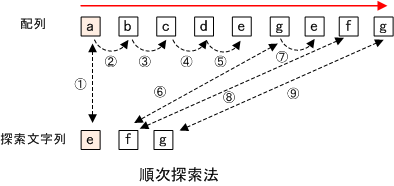
- 配列の先頭と文字列の先頭を比較 ( a : e )
- 一致しないので配列の1つ右の文字と比較 ( b : e )
- 一致しないので配列の1つ右の文字と比較 ( c : e )
- 一致しないので配列の1つ右の文字と比較 ( d : e )
- 一致しないので配列の1つ右の文字と比較 ( e : e )
- 一致したので配列の1つ右の文字と文字列の二文字目を比較 ( g : f )
- 一致しないので配列の1つ右の文字と文字列の先頭を比較 ( e : e )
- 一致したので配列の1つ右の文字と文字列の二文字目を比較 ( f : f )
- 一致したので配列の1つ右の文字と文字列の三文字目を比較 ( g : g )
すべて一致したので探索終了
順次探索法のフローチャート(擬似言語)
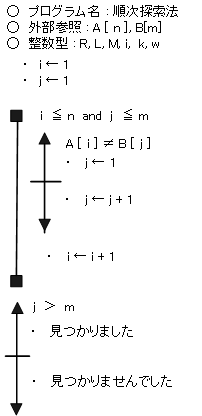
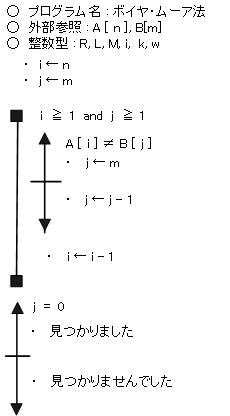
- ボイヤ・ムーア法
配列は先頭から、文字列は最後尾から探索していく方法。
配列の文字が、探索文字列のどれにも一致しない場合は、配列を探索文字列数分一気にずらすことができる。
- 探索文字列と配列の先頭をそろえます。
- 探索文字列の末尾 ( これを探索文字列の先頭から m 文字目とします ) の文字と、配列の m 文字目の文字を比較します。
- 一致したら探索文字列の文字を一つ前(m - 1)にずらし、配列の文字の一つ前にずらした文字(m - 1)と比較する。これを探索文字列の先頭まで、末尾側から前方向に比較していきます。
- 不一致になった場合、探索文字列の文字を一つ前にずらし、その文字と配列の文字を比較します。この処理を探索文字列の先頭まで、前方向に比較していきます。
- もし4.の処理で先頭まで比較し、不一致を引き起こした配列の文字が、探索文字列中に含まれていたら、両者が重なる位置まで探索文字列を右にずらします。そうしないと、同じ場所で再び不一致を検出してしまうからです。
- 4.の処理で、不一致を引き起こした配列の文字が探索文字列中に含まれていない場合、不一致を起こした配列の文字から数えて探索文字列分一気にずらします。そして、2.の処理に戻り、処理を継続します。
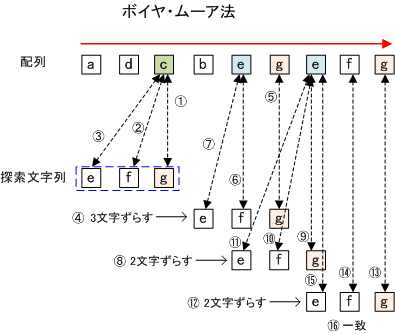
- 配列の3文字目と探索文字列の最後を比較 ( c : g )
- 一致しないので探索文字列の1つ左の文字と比較 ( c : f )
- 一致しないので探索文字列の1つ左の文字と比較 ( c : e )
- 配列の3文字目は探索文字列のどの文字とも一致しないので配列を3つ右にずらす
- 配列の6文字目と探索文字列の最後を比較 ( g : g )
- 一致したので配列の1つ左の文字と探索文字列の1つ左の文字を比較 ( e : f )
- 一致しないので探索文字列の1つ左の文字と比較 ( e : e )
- 配列の5文字目が探索文字列の中に在る文字と一致したので配列を右に1つずらす
- 配列の7文字目と探索文字列の最後と比較 ( e : g )
- 一致しないので探索文字列の1つ左の文字と比較 ( e : f )
- 一致しないので探索文字列の1つ左の文字と比較 ( e : e )
- 配列の7文字目が探索文字列の中に在る文字と一致したので配列を右に2つずらす
- 配列の9文字目と探索文字列の最後と比較 ( g : g )
- 一致したので配列の1つ左の文字と探索文字列の1つ左の文字と比較 ( f : f )
- 一致したので配列の1つ左の文字と探索文字列の1つ左の文字と比較 ( e : e )
- すべて一致したので探索終了。探索文字列は配列の中に存在する。
ボイヤ・ムーア法のフローチャート(擬似言語)
ファイルを処理するためのアルゴリズム。
- 整列処理
ファイルをある基準に従って並べ替える処理 - 併合処理
データ構成が同じ複数のファイルをある基準で並べ替えながら、1つのファイルにする処理 - コントロールブレーク処理
ある基準のグループごとに、数値項目の集計する処理
- 平成30年度春期 問07 ハッシュ法
- 平成30年度秋期 問06 クイックソート
- 平成27年度春期 問06 2分探索法
- 平成27年度秋期 問07 ソート
- 平成26年度秋期 問06 2分探索
- 平成23年度春期 問08 クイックソート
- 平成22年度春期 問06 ハッシュ表
- 平成22年度秋期 問07 ハッシュ法
- 平成21年度春期 問02 ハッシュ表
- 平成21年度春期 問07 2分探索法 比較回数
www.it-shikaku.jp