基礎理論 - 1.基礎理論 - 3.情報に関する理論 - 2.符号理論
様々な情報を数値に変換して、情報量として表現することを符号化という。
符号理論(Coding theory)は、情報を符号化して通信を行う際の効率と信頼性についての理論である。数学や情報理論と深く関わっている。
情報源符号
情報源で転送前のデータをより効率的に圧縮することを目的とする符号化
ハフマン方式やランレングス符号化方式などがある。
- ハフマン符号化方式
ファイル圧縮の技術の一つで、可逆圧縮で、文字コードのビット数を可変にすることで、出現率の高い文字には少ないビット、滅多に出ない文字には長いビット数を割り当てるというもの。 - ランレングス符号化方式
主に画像データの圧縮に用いられる符号化方式の一種で、連続する同一の値を「色×回数」という列の長さ(run-length)の情報に置き換える方式のことである。
ランレングス符号化では、例えば画像の中に「白白白黒黒黒黒白黒黒」というデータの並びがあった場合、「白3黒4白1黒2」というデータに変換される。ランレングス符号化は単純な画像データほど効果的な圧縮が可能であり、可逆圧縮であるため完全にデータを再現できるというメリットを持っている。FAXなどではランレングス符号化によるデータ圧縮方式が採用されている。
- ハフマン符号化方式
伝送路符号(通信路符号化)
データ伝送時に通信路上の雑音に対応するため、冗長ビットなどを付加して雑音などへの耐性を増やすための符号化
誤り検出や誤り訂正方法にリードソロモン符号方式・FEC・CRCなどがある。
- リードソロモン符号方式
誤り訂正符号の一種。バースト誤り検出/訂正用のブロック符号方式(block code)の1つ。通信やデータ記録で利用する。
ブロック符号方式とは、伝送する情報ビットをある大きさのブロックに分け、ブロックごとにパリティ・ビット(誤り検出用ビット)を付加する方法をいう。 - FEC
一方向誤り訂正とも。前方誤り訂正の利点は、データの再送を防ぐことで高スループットを平均的に達成する点である。このため、再送がコスト高になる場合や不可能な場合に適用される。 - CRC
連続する誤りを検出するための誤り検出符号の一種。
- リードソロモン符号方式
コンパクト符号という符号化の一種で、一意に復号可能な符号のうち平均符号長が他より小さい符号のことを言います。
一意とは、2つ以上の値が存在しないことです。つまり、復号する際に解釈の違いによって復号後の結果が異ならないということを意味します。平均符号長とは、名前の通り全体の符号長の平均です。符号化前の符号の平均の長さより、符号化後の平均の長さが短くなれば圧縮成功となります。
コンパクト符号の一種であるハフマン符号は『復号後の結果はちゃんと元の符号に戻ることができ、かつ全体のデータ量を減らすことができる符号化』ということになります。各記号の出現確率を事前に求め、出現度の高い文字を短い符号で、出現率が低い文字を長い符号で表現することで、平均符号長を最小とする圧縮技術です。
● 符号化の手順
データ「ACBDBCBABECABCD」をハフマン符号化してみます。
まず、圧縮しない符号化の場合、
| A | 000 |
| B | 001 |
| C | 010 |
| D | 011 |
| E | 100 |
を割り当てると、先ほどの文字列は、
| A | C | B | D | B | C | B | A | B | E | C | A | B | C | D |
| 000 | 010 | 001 | 011 | 001 | 010 | 001 | 000 | 001 | 100 | 010 | 000 | 001 | 010 | 011 |
割り当てた符号の長さがすべて一定であるものを「固定長符号」といいます。
文字列のバイト数は、3bit×15文字=45bitになります。
これをハフマン符号化するには、まず文字の出現回数を数えます。そして出現頻度順にソート(並び替え)します。
| 文字 | 出現回数 |
| B | 5 |
| C | 4 |
| A | 3 |
| D | 2 |
| E | 1 |
この表から「ハフマン木(Huffman tree)」を作っていきます。
- まず1番下に出現頻度の一番少ないものと2番目に少ないものを置きます。(DとE)
- ふたつの出現数を足して、ひとつ上に新しい「節」を作ります。
- その「節」とそれぞれを「枝」で結びます。
- 次に出現数の少ないもの(A)と今作った「節」との、ふたつの数を足して、ひとつ上に新しい「節」を作ります。
- その「節」とそれぞれを「枝」で結びます。
- これを繰り返して木を完成させます。
- 各階層のそれぞれの枝に0と1を割り当てます。左の枝に0を割り当てたら、右の枝に1を割り当てます。各階層は同じルールで割り当てます。
- 上からそれぞれの文字まで枝をたどって行き、通った枝の0と1をひかえて、その文字までのコードを作成します。
たとえば、Aだと1→1→0でA=110で表す。
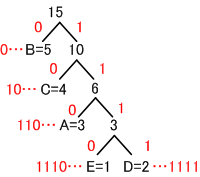
これをもとにコード表を作成する。
| 文字 | 出現回数 | コード |
| B | 5 | 0 |
| C | 4 | 10 |
| A | 3 | 110 |
| D | 2 | 1111 |
| E | 1 | 1110 |
このコードを割り当てると、先ほどの文字列は、
| A | C | B | D | B | C | B | A | B | E | C | A | B | C | D |
| 110 | 10 | 0 | 1111 | 0 | 10 | 0 | 110 | 0 | 1110 | 10 | 110 | 0 | 10 | 1111 |
ビット数は、34bitになる。圧縮率は34/45=0.756
元に戻すには、
ピット列と先ほど作ったコード表を使って、先頭からコード表にあるコードを割り当てていく。
1101001111010011001110101100101111
- 先頭ビットは1なので、コード表にない。2番目のビットと合わせて、11これもコード表にない。3番目のビットと合わせて、110これはコード表のAになる。
- 次のビットから初めて、1これはないので、次のビット0、10これはコード表のCになる。
- 次のビットは0で、これはコード表のBになる。
- これを繰り返していく。
ハフマン符号では、コード表の各文字に対する符号化で「全く同じビットの並びが存在しない」ような符号化をしている。
文字を判定している途中で元の文字以外の符号パターンが存在しないような符号化をします。
ビット数の少ないビットパターンがビット数の多いビットパターンの中にないということ。
A=1111、B=111がもしコード表に載っていると、もとのビットに1111があった場合、本来はAの文字なのだが、3ビットで判定してBになってしまう。
そのようにならないように文字にコードを割り当てている。
アナログの信号は連続した値をとる信号で、デジタル信号は飛び飛びの値を持つ信号
音声データや画像・写真などのアナログデータをコンピュータで利用するためには、デジタルデータに変換する必要がある。
このアナログデータをデジタルデータに変換することをA/D変換と呼ぶ。
A/D変換は、一般的に 標本化 → 量子化 → 符号化 の順で行われる。
【 標本化(サンプリング) 】
波形を一定の時間で区切る。
区切りと波の交点を標本点
区切る間隔を標本化周波数(サンプリング周期)
【 量子化 】
標本点の値にもっとも近い整数値を求める。
振幅を区切る間隔を短くすると、元の波形に近くなる。
もとのアナログ値との誤差を量子化誤差という
【 符号化 】
標本化と量子化によって得られた数値を n ビットの 2 進数に変換する。
n の値が大きいほど精度に優れるがデータ量は大きくなる。
たとえば、サンプリング周波数を 8kHz で、8 ビットで符号化すると、1 秒間のデータ量は
8000 × 8 = 64000 ビット = 64k ビット
になる。
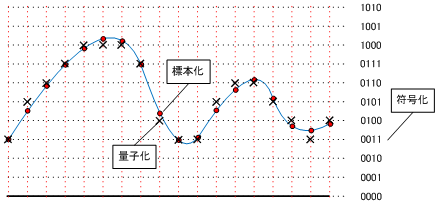
- 平成31年度春期 問25 音声のサンプリング
- 平成28年度春期 問04 音声 サンプリング
- 平成28年度秋期 問25 記録容量 サンプリング
- 平成26年度秋期 問31 バッファ
- 平成25年度春期 問03 サンプリング
- 平成25年度秋期 問04 サンプリング
- 平成24年度春期 問26 サンプリング
- 平成23年度春期 問03 符号化
- 平成23年度春期 問14 A/D変換 サンプリング
- 平成21年度秋期 問30 記録容量 サンプリング
www.it-shikaku.jp